What I learned creating 12inch.reviews, a mashup of Spotify and Pitchfork
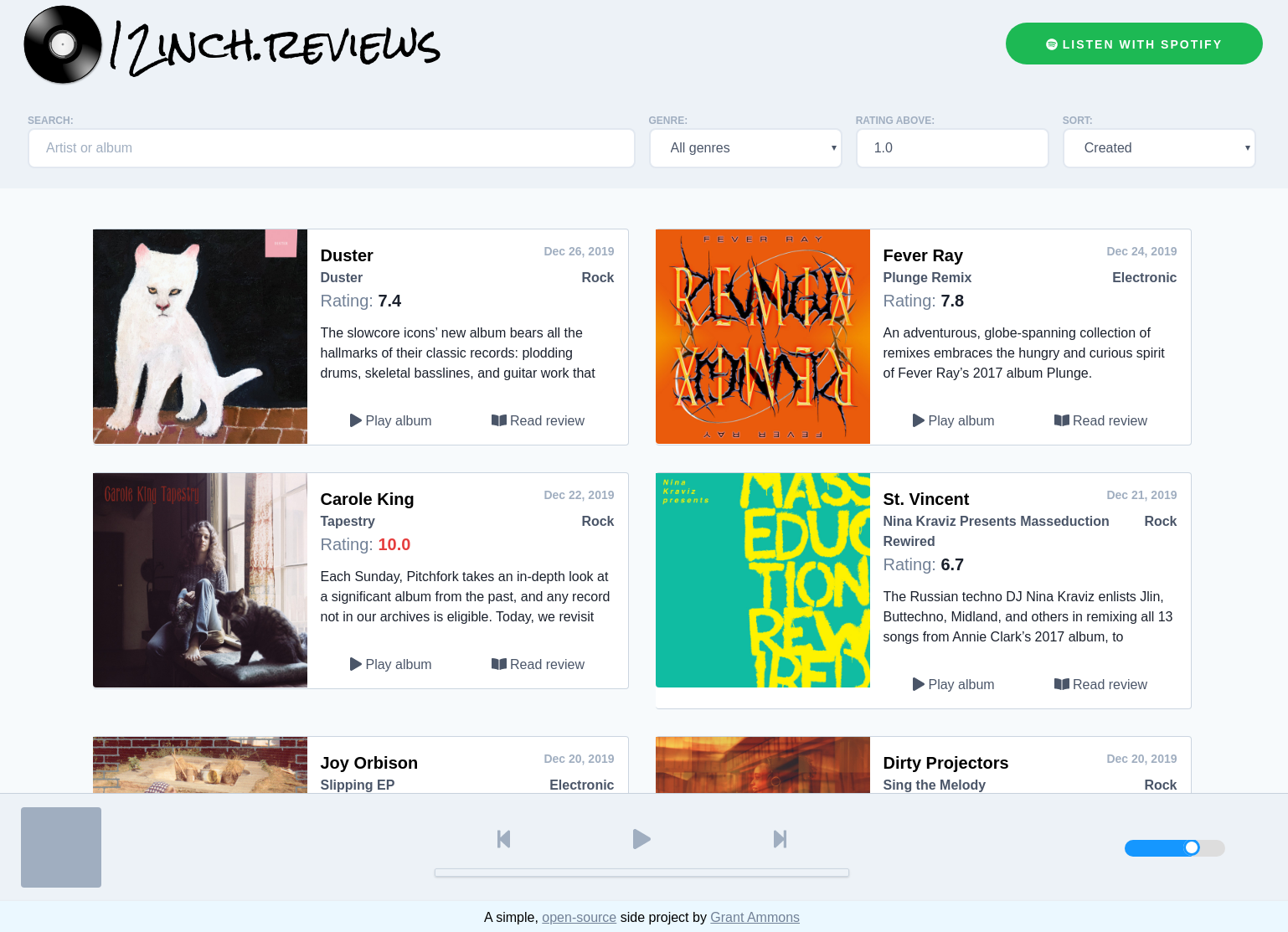
I’m a huge music nerd. I’ve played in many bands in my teens 20s, and music is a big part of my life.. I’m also a big fan of Pitchfork music reviews.
There was a mashup site I was using called Pitchify, which was no longer updating, and it eventually got taken down. So I did what any engineer would do and I created my own mashup!
12inch.reviews is a mashup of Pitchfork’s album reviews with Spotify’s web playback SDK. It utilizes the browser’s IndexedDB API to allow for fast, responsive searching and sorting of 17k+ album reviews, and allows you to play the full album right in the browser!
As with any side project, I had a few learning goals in mind that I wanted to bake in:
- Continue to invest in learning React, specifically React hooks, and progressive web apps.
- Learn tailwind.css
- I wanted it to include all of Pitchfork’s reviews, and have them be easily searchable. There are a lot of seminal albums that I just haven’t had exposure to. Being able to find them easily would be a requirement.
- I wanted to leverage different and interesting browser technologies to keep the main functionality of this site all on the frontend.
- I wanted it to be completely completely open source.
Pitchfork has over 20k reviews on their site, so being able to store that many records on the frontend, specifically in Javascript, would be a challenge. Each browser has different storage quotas that aren’t particularly well-documented. So I needed to think about how to work around these quotas in a seamless and transparent way.
The backend
12inch.reviews uses a simple(ish) retriever script script that does the following:
- utilizes Pitchfork’s undocumented API to find new albums since the last time the script was run
- Attempts to find that album using Spotify’s search API.
- If found, add that album to a simple SQLite DB
There is another backend function that will take the contents of the SQLite DB and to create a series of JSON files, which includes all the data the frontend needs. The structure of each JSON album looks like so:
{
"id": 13501,
"pitchfork_id": "5929e2d1eb335119a49ef060",
"title": "Out of Tune",
"artist": "Mojave 3",
"rating": "6.3",
"bnm": false,
"bnr": false,
"label": "4AD",
"url": "https://pitchfork.com/reviews/albums/5376-out-of-tune/",
"description": "Out of Tune is a Steve Martin album. Yes, I'll explain: Once upon a time, there was ...",
"genre": "Rock",
"spotify_album_id": "2TLUvacBePI5753CqHPpxF",
"spotify_artist_id": "4jSYHcSo85heWskYvAULio",
"image_url": "https://i.scdn.co/image/ab67616d0000b27360b1fa1c0a15bcb97f9544a2",
"page": null,
"created_at": "1999-01-12 06:00:00 UTC",
"updated_at": "2019-10-25 12:33:03 UTC",
"timestamp": 916120800
},
Once the JSON files are created, they are uploaded to S3 for the frontend to use. Each album entry has all the info needed in order for Spotify’s web SDK to use them on the frontend, and to be searchable.
The retriever Rakefile also has functions to backfill all albums (takes multiple hours!) and has some utility functions to be able to create a new SQLite DB and other functions to massage the data into the correct format.
The main task, refresh_and_upload runs hourly. Currently it’s running as a Kubernetes CronJob on my homelab Kube cluster (I’ll talk more about that in another post).
Netlify Lambda functions
12inch.reviews is hosted on Netlify, mainly because Netlify is amazing. It provides a seamless CI/CD pipeline, SSL, and AWS Lambda-like functions - all for free.
I use these functions to “log in” a user via Spotify Oauth. I would have done this all on the frontend, except for the fact that Oauth requires a secret token and that can’t be exposed on the frontend.
Since Spotify’s access tokens are short-lived (1 hour max!) there is also a secondary function that will renew an access token seamlessly upon playback.
Once an access token is obtained, state is stored via the browser’s LocalStorage API.
The frontend
The frontend of 12inch.reviews is a relatively simple create-react-app single-page app, that provides search and sort functionality, as well as the ability to play any album using Spotify’s web playback SDK.
Getting all the album data
When you visit 12inch.reviews the first time, it will show the albums from a small JSON file called initial.json. This file includes only the first 25 most recent albums, so we have something to paint on the screen.
Then, the rest of the album data will be backfilled in via a series of fetches to retrieve all of the JSON files. I decided to partition each JSON file with 1000 albums, so there are 17 files altogether. Each album JSON file is at least 600k uncompressed, so there is probably room for more optimization here.
After each JSON file is retrieved, they are stored in an IndexedDB on the frontend. Subsequent visits to 12inch.reviews don’t require the large JSON payload - it will only load the delta payloads into the DB. I’m taking advantage of the fact that these reviews are immutable - once they are written they will never change.
Searching albums
Although IndexedDB is great for storing this data, there is currently no functionality to actually query IndexedDB like a regular database. So in order for 12inch.reviews to do searching and sorting, all of the data must be loaded into a simple javascript array.
Playing albums
I utilized Spotify’s Web playback SDK to do the actual playing. It provides a series of hooks to use in order to initialize the player, and to do the actual playing.
I wrapped the actual playing into a simple class that ensures a refreshed access token is always provided.
The player component is one of the most complex react components in the app. Although the web playback SDK has its own state, I had to essentially “sync up” the player component’s state with the SDK’s state. As with any type of synchronization, there are probably bugs keeping these 2 things in sync with each other.
The [progress bar][progress_bar] is clickable and utilizes some simple CSS animations to look and feel like a regular music progress bar.
IANA designer, but I was heavily influenced by Tesla’s UX when designing the player component.
Criticism of Spotify’s Web Playback SDK
My experience with Spotify’s web playback SDK has been sub-par. The SDK does not have a package.json file, and therefore is not in the npm universe. There isn’t an easy way to hook the SDK into a React or Vue app. This required a lot of manual syncing code that is probably hiding bugs.
They have a public issue tracker on Github, but many of the issues don’t have answered questions.
It’s hard for me to understand who the target audience was for this SDK. I think it would benefit greatly from being open source and part of the NPM ecosystem. This would allow others to create wrappers for popular frameworks, which would allow me to remove my terrible syncing code.
Lessons learned + planned optimizations
This was a really fun project to work on. It took me about 6 weeks of coding, utilizing my “side project hours” (roughly 5:30am - 7am on weekdays).
I learned a bunch of things:
- Tailwind.css
- IndexedDB
- Netlify Lambda Functions
- Spotify’s APIs
12inch.reviews is a toy. It has enormous shortcomings, mainly the fact that it needs to backfill nearly 20Mb of album review data in order to work well. This is insanely inefficient and wouldn’t be appropriate for anything other than a personal side project site coded for educational purposes.
Other shortcomings: * I don’t feel like I leaned into Flow types as much as I could. * Overall performance is still not great, as measured by Chromes Dev Tools. * I should utilize a service worker to populate the indexeddb. * Could create a GraphQL backend to do the data serving, to alleviate the need to bring all 20MB of data to the frontend.